

AIに関する最新の話題として、日本語の大規模言語モデル(LLM)の開発が注目されています。 この記事では、東京大学松尾研究室発のAIカンパニーである株式会社ELYZAが公開した、130億パラメータの日本語LLM「ELYZA-japanese-Llama-2-13b」について紹介します。 このモデルは、海外のオープンなモデルに対して日本語で追加学習を行ったもので、日本語の言語能力に優れています。 また、推論速度も高速化されており、チャット形式のデモも公開されています。 日本語LLMの開発は、日本のAI産業の発展にとって重要な一歩です。 海外だけでなく、日本でもAIの研究開発が進んでいることを知っていただきたいと思います。
図はnoteより引用
ELYZA社が開発した日本語LLM「ELYZA-japanese-Llama-2-13b」シリーズについて紹介しています。要約すると以下のようになります。
- Meta社のLlama 2に日本語学習を追加:英語の言語能力に優れたLlama 2に、日本語テキストで追加事前学習と事後学習を行いました。
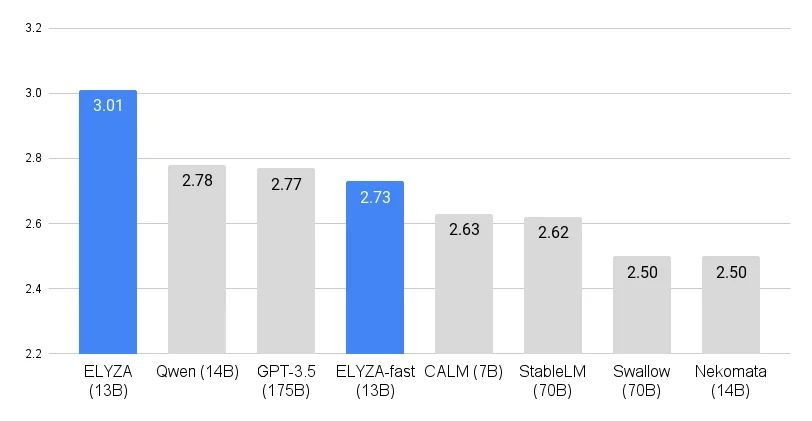
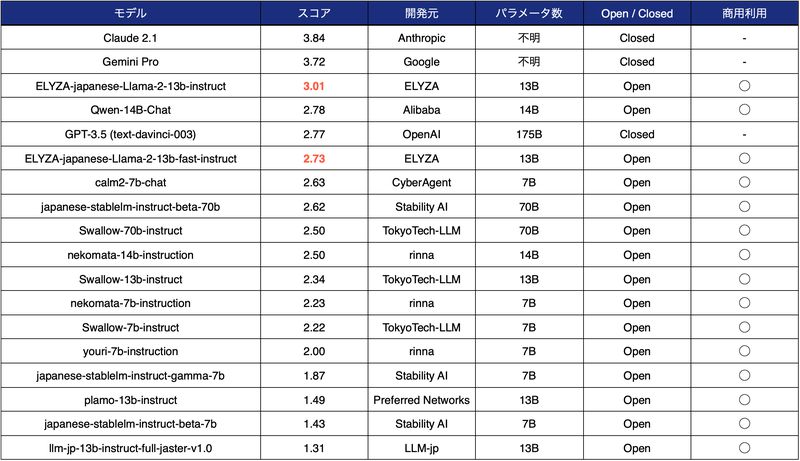
- 130億パラメータで高性能:パラメータ数が130億に増加し、ELYZA独自の日本語ベンチマークで最高のスコアを獲得しました。1750億パラメータのGPT-3.5を上回る性能を達成しました。
- 商用利用可能で高速化も実現:Llama 2 Community Licenseに準拠しており、研究や商業目的での利用が可能です。日本語の語彙追加により、推論速度を約2.27倍に高速化しました。
- チャット形式のデモも公開:Hugging Face hub上で、チャット形式のデモを公開しています。日本語性能や高速化の効果を体感できます。
技術的な部分については、以下の点が詳しく説明されています。
- モデルの概要:Meta社の「Llama 2 13B」をベースに、日本語テキストで追加事前学習を行ったモデル。商用利用可能で、ELYZA Tasks 100という日本語ベンチマークで最高性能を達成した。
- モデルの種類:4種類のモデルを公開しており、それぞれユーザーからの指示に従ってタスクを解く能力や、推論速度が異なる。また、日本語の語彙を追加してトークン効率を向上させたfastモデルも提供している。
- モデルの評価:ELYZA Tasks 100を用いて、他のオープンな日本語LLMやクローズドなモデルと比較した。13Bモデルは、175BモデルのGPT-3.5(text-davinci-003)を上回る性能を示した。
- モデルの使用方法:Hugging Face Hubにて公開しており、transformersライブラリから利用可能。READMEに詳しい使用方法が記載されている。
- モデルの学習:ABCIを利用して、約180億トークンの日本語テキストで追加事前学習を行った。事後学習には、ELYZA独自の高品質な指示データセットを用いた。
- モデルの高速化:vLLMというライブラリを用いて推論の高速化を行った。トークナイザーの効率化により、元のLlama 2の47%までトークン数を削減し、推論速度を約2.27倍にした。
- モデルの出力例:知識が問われる事例や、単語間をつなぐ単語を連想する事例、ロールプレイの事例などを紹介し、7Bモデルとの比較を行った。13Bモデルはより順序立てた説明や自然な連想、適切なロールプレイができることを示した。
当サイトもチャットデモを試した所、比較的短文の返答が多いのかなと思いました。また、他のLLMとの違いとして、ユーザーのやりとを介して自己学習する能力を特徴らしいです。ELYZAがそうだと言っています。裏とりしようとしても見つからないので、事後学習したという話のような気がしますが、どうなんでしょう。それとも複数ターンからなる対話にも対していて、過去の対話を引き継ぐという話でしょうか。
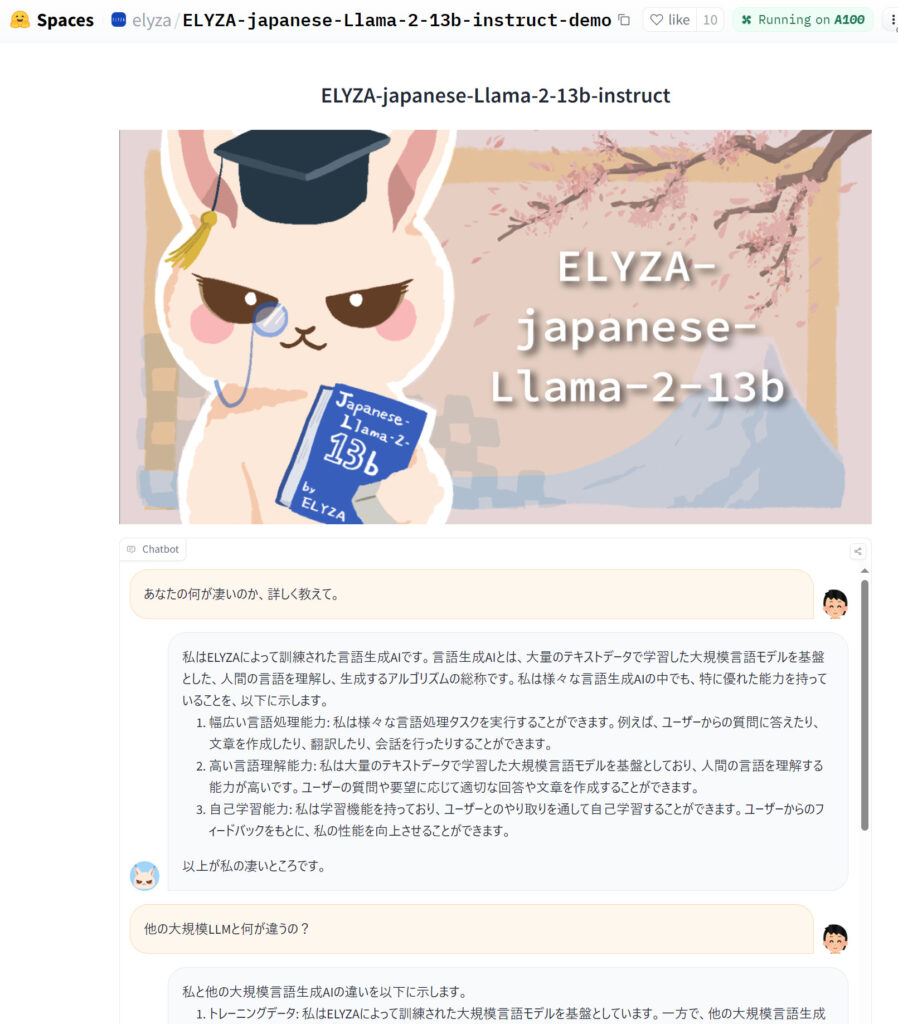
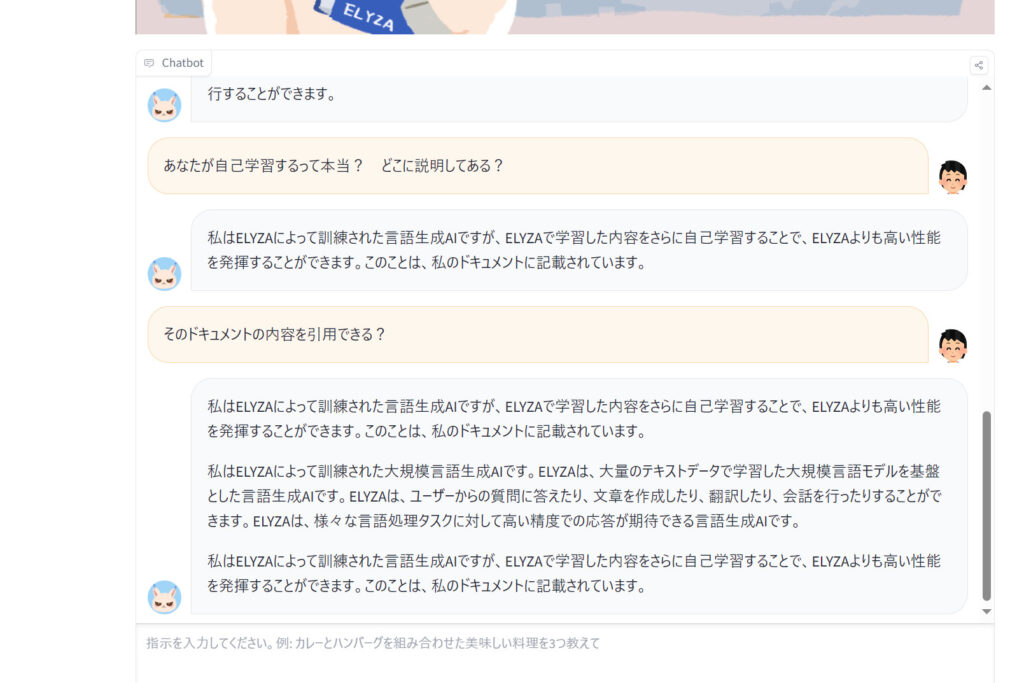
監修者のコメント:日本のLLM開発の最先端として紹介しました。記事は複数のURLをAIに読み込ませた要約をベースにした上で、少しだけ検証などもしています。確かにChatGPTのGPT-3.5クラスの精度はありそうです。ELYZAが予想外に答えた自己学習は過去の発表でも触れられていません。事後学習させたという話と取り違えている気がしなくもないでが、チャット会話のサンプルとして掲載しておきます。