

大規模言語モデルの学習精度をどう向上させていくのかーー 米Metaと米ニューヨーク大学の研究者らが提案した、自分自身に報酬を与えて繰り返し学習する大規模言語モデル(LLM)、自己報酬型言語モデルを開発、arxivで公開しました。
自分で問題作り自分で回答し自分で評価しその結果を学習データに使用。論文ではLlama 2 70Bという言語モデルを、Open Assistantというデータセットでファインチューニングした後、自己報酬型言語モデルの学習を3回行いました。その結果、指示に従う能力と報酬モデルとしての能力がともに向上し、AlpacaEval 2.0という評価指標で、Claude 2やGemini Proなどの既存のシステムを上回る性能を達成しました。
この研究は、人間の指示や報酬に依存しない、自律的な言語モデルの開発に貢献する可能性のある技術です。
自己報酬型言語モデルとは
言語モデルとは、自然言語の文や単語の生成や理解を行う人工知能の一種です。近年、大規模なデータと深層学習の技術により、言語モデルの性能は飛躍的に向上しました。しかし、言語モデルはまだ人間の指示に従って動作することが多く、自分で目標や報酬を設定して学習することはできませんでした。
自己報酬型言語モデルは、この問題に挑戦した新しい研究です。この言語モデルは、二つの能力を同時に持ちます。
- 指示に従う能力:ユーザーからの要求に対して、適切な回答を生成する能力です。
- 自己指示生成能力:自分で新しい指示と回答の例を生成し、評価する能力です。
この言語モデルは、自己指示生成能力を使って、自分自身に報酬を与えます。つまり、自分で作った指示と回答のペアに対して、その質や正確さを判断し、点数をつけます。この点数は、自分の学習の指標となります。このようにして、言語モデルは自分で自分を改善していくことができます。
自己報酬型言語モデルの学習方法
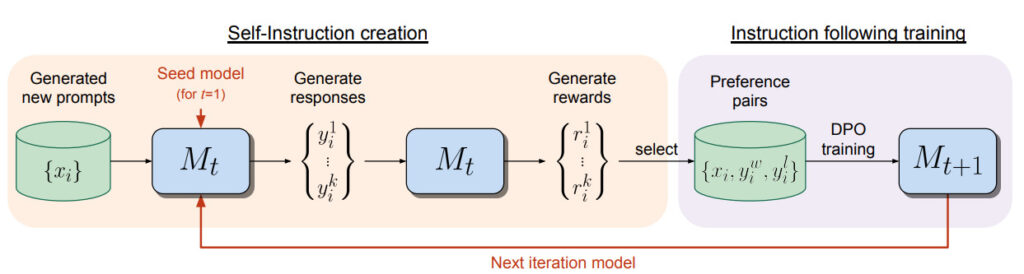
自己報酬型言語モデルの学習方法は、反復的な手順で行われます。最初に、既存の言語モデルと少量の人間が作った指示と回答のデータを用意します。次に、以下のステップを繰り返します。
- 自己指示生成:言語モデルが新しい指示を生成し、その指示に対して複数の回答候補を生成します。次に、言語モデルが自分で回答候補の質を評価し、点数をつけます。
- 指示に従う学習:言語モデルが生成した指示と回答のペアから、優れた回答と劣った回答のペアを選びます。これらのペアを用いて、言語モデルを学習させます。学習の方法は、直接優先度最適化という手法を使います。これは、優れた回答の確率を高め、劣った回答の確率を低めるように言語モデルを調整する手法です。
この反復的な学習により、言語モデルは自分で自分の学習データを増やし、改善していきます。また、指示に従う能力だけでなく、自己指示生成能力も向上します。つまり、言語モデルは自分で自分により高品質な報酬を与えることができるようになります。
自己報酬型言語モデルの実験結果
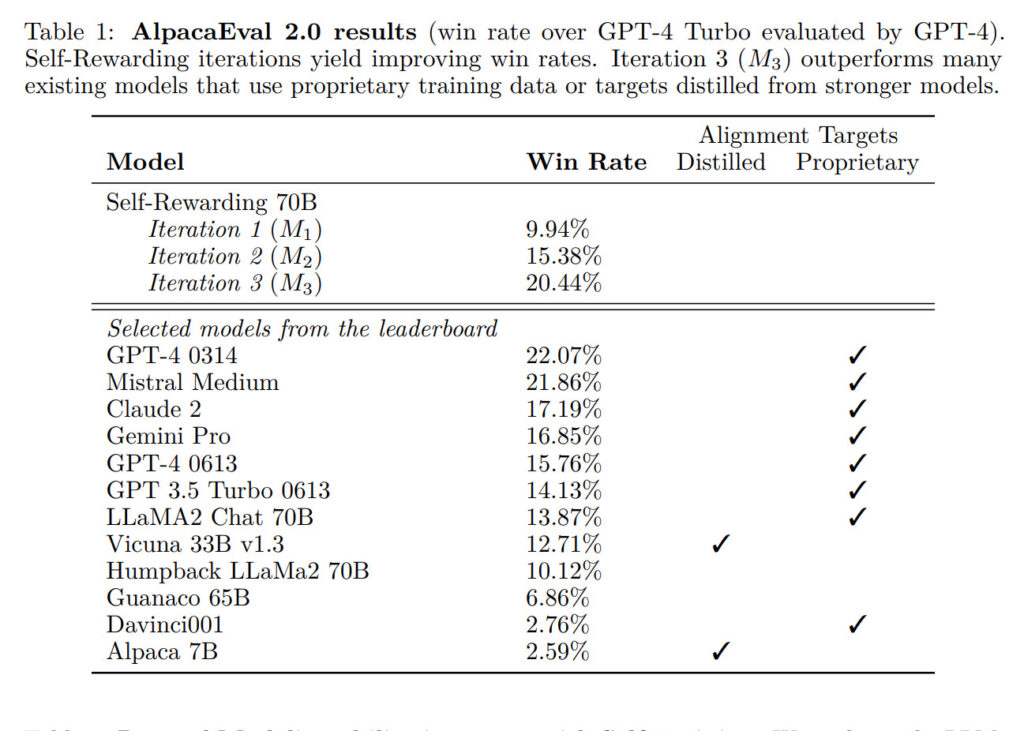
自己報酬型言語モデルの実験結果は、非常に優れています。研究者たちは、Llama 2 70Bという70億パラメータの言語モデルをベースにして、自己報酬型言語モデルを作りました。そして、Open Assistantという指示と回答のデータセットを用いて、3回の反復学習を行いました。
その結果、自己報酬型言語モデルは、指示に従う能力だけでなく、自己指示生成能力も大幅に向上しました。指示に従う能力は、GPT-4という最先端の言語モデルを使って評価しました。その結果、自己報酬型言語モデルは、Claude 2やGemini Pro、GPT-4 0613といった既存のシステムを上回る性能を示しました。自己指示生成能力は、人間が作った指示と回答のペアのランキングとの一致度で評価しました。その結果、自己報酬型言語モデルは、反復学習ごとに一致度が高まり、より正確な報酬を与えることができるようになりました。
この技術により、言語モデルは自分で自分の学習データを増やし、改善していくことができます。また、指示に従う能力だけでなく、自己指示生成能力も向上します。この技術は、人間の指示や報酬に依存しない、自律的な言語モデルの開発に貢献する可能性があります。
参照元:レバテックLAB